

Tracking digital footprints with username and alias correlation
Techniques for correlating usernames, visuals, and content to unmask anonymous sources


In the digital age, individuals can conceal their true activities by relying on digital fragmentation, scattering their activities across multiple social media accounts, forums, and platforms with slightly varied or entirely different usernames (aliases).
For investigative journalists, the challenge is not just finding the data but confirming identity. For example, proving that “SecureNinja23” on a dark web forum and the writer of a leaked internal memo are the same person.
This skill of identity stitching, or alias correlation, is the most important one for creating a verifiable, cross-platform digital footprint that connects online activity to a person or organisation.
👁️ Goals for learning
Master the use of automated and manual tools to cross-reference a single username across public platforms.
Develop techniques for confirming identity through subtle digital patterns (e.g., bio reuse, profile photo consistency, writing style).
Implement a rigorous process for capturing and preserving evidence that is correlated (Chain of Custody).
Understand the ethical line between public data correlation and illegal/unauthorized access.
💡 Basic ideas
Key terminology
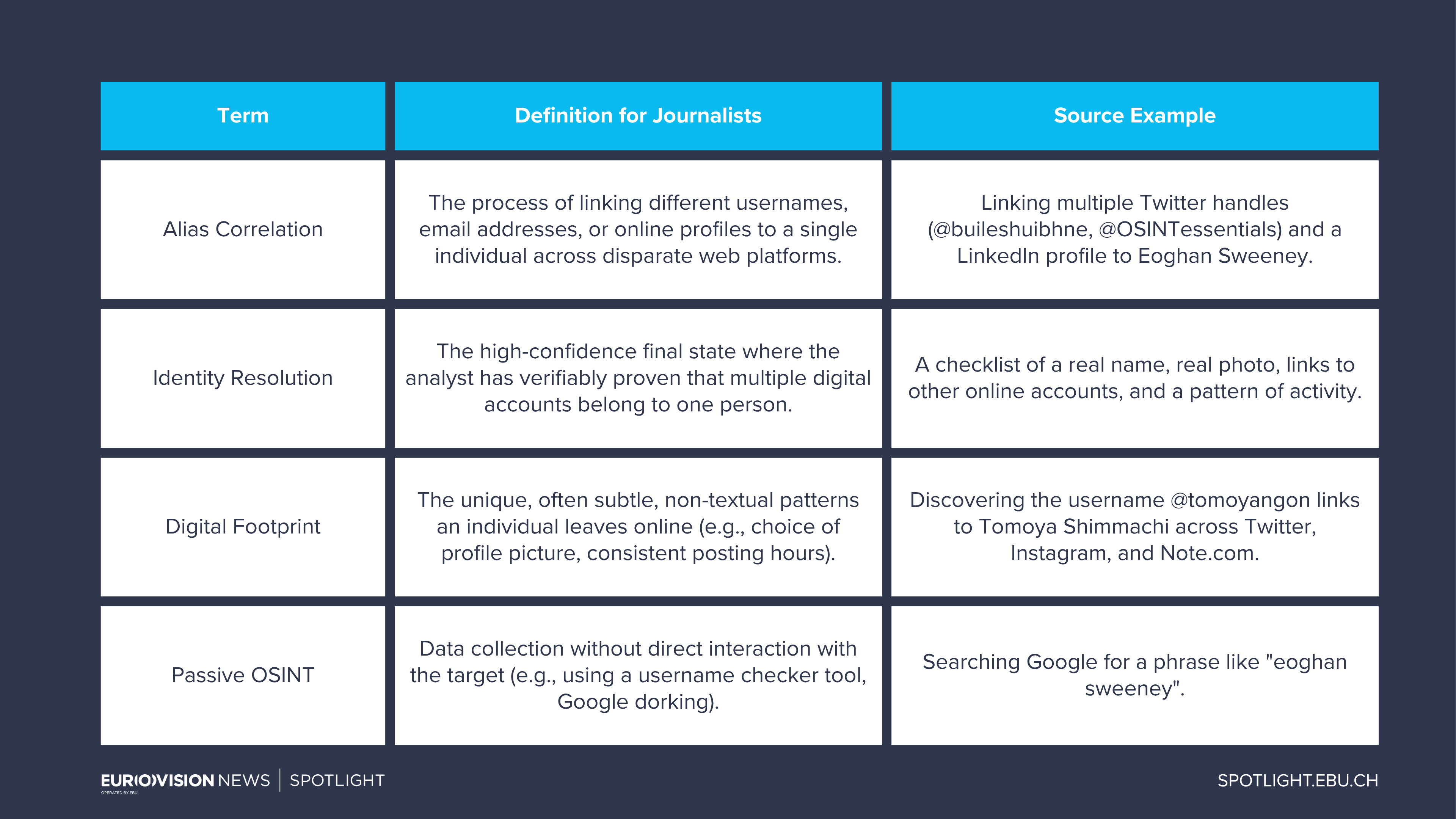
⚠️ Important for journalists: Ethical and legal limits
You must limit your research exclusively to publicly accessible data.
The Golden Rule: Stop immediately at any login prompt. Any attempt to bypass a login, whether by guessing a password, using leaked credentials, or exploiting a technical vulnerability, crosses the line from ethical OSINT into unauthorized access/hacking, which is illegal and unethical.
Data sensitivity: Information found in the public domain (e.g., a photo on a public social media profile) is fair game. However, publicly exposing highly sensitive personal data (e.g., unredacted home addresses, private medical information) must be justified by a clear, overriding public interest and vetted by your legal and editorial teams.
The laws governing unauthorized computer access (like the Computer Fraud and Abuse Act (CFAA) in the US) are broad. Being blocked by a website’s Terms of Service (ToS) or a technical gate could be interpreted as unauthorized.
Risk Mitigation: Never use tools designed to force access or exploit vulnerabilities (like Shodan/Censys for non-public data) unless you have extensive legal guidance.
Mandatory Legal Disclaimer: The information and techniques provided here are for educational and journalistic verification purposes only. Investigative journalists must consult their own legal department and editorial guidelines before acting on any information involving complex legal jurisdictions, data privacy (such as GDPR), or potential intrusion into private systems or accounts.
🛠️ The Method: Putting it into action step-by-step
Required tools & setup
👷♀️ How to put it into practice
Scenario: Resolving the Identity of an account linked to a misinformation network
Goal: Link a suspected misinformation account (Alias: @ShadowWhisper_007) on platform X to any other public profile to begin building a full identity.
Initial scan (Username enumeration):
Input the core username (
ShadowWhisper_007) into WhatsMyName or Namechk.Crucial step: Systematically test subtle variations:
ShadowWhisper007,ShadowWhisper\_,S_Whisper007. An alias often follows a pattern.
Visual correlation (Profile picture pivot):
Download the
@ShadowWhisper_007profile picture (ensure it’s publicly available).Run a reverse image search (Yandex is excellent for faces/avatars).
Investigative value: Finding the same picture on a platform like a forgotten LinkedIn profile or a niche gaming forum provides high confidence of correlation.
Content/pattern analysis (Digital footprinting) - manual techniques:
If a second profile is found (e.g., a blog or forum post), compare the content.
Focus on the pattern:
Do they use the same catchphrases?
Do posts on both accounts stop/start at the same time?
Do they both mention the same niche, non-public event or location?
Manual correlation checklist (The cognitive step):
Linguistic Style: Search for consistent, unique linguistic markers:
Unusual punctuation (e.g., excessive ellipses, lack of capital letters)
Repeated grammatical errors, or specific, niche terminology only used in certain industries.
Chronolocation: Analyze the time zone and consistent posting hours across both profiles. A user posting consistently at 2:00 AM EST on one platform and 7:00 AM CET on another suggests a specific geographic location.
Bio reuse: Search for exact, non-generic phrases used in the “About Me” or bio section of the first alias to see if they appear anywhere else.
Metadata pivot: If the correlating platform allows file uploads, check the public metadata (EXIF) of any uploaded images for camera models, software used, or even geolocation hints.
Data visualization (Maltego step)
For investigations involving more than two platforms, use a visualization tool like Maltego (or even a simple drawing tool/spreadsheet) to map the connections.
Execution: Input each correlated data point as an entity (e.g., Username 1, Username 2, Email Address, Profile Photo Hash, Unique Phrase) and draw the confirmed links.
Value: Visualization is key for complex identity stitching. It highlights the strongest, most complex linkages (e.g., two different usernames sharing a single IP address and profile photo) for fast, high-confidence confirmation.
Actionable correlation table: Linking data points
💾 Keeping data safe: The audit trail
For any correlated identity to be admissible evidence in journalistic reporting (and potentially a legal context), you must ensure a Chain of Custody.
Immediate archiving: Use tools like FireShot (full-page capture) or perma.cc to capture a snapshot of the source page immediately upon discovery.
Metadata logging: Document the following in a structured log (spreadsheet):
Date and timestamp (UTC): When the source was accessed.
Source URL: The exact URL of the publicly accessible page.
Method used: (e.g., “WhatsMyName check,” “Yandex Reverse Image Search”).
The finding: A precise description of the correlation point found.
Hashing the evidence: For every screenshot or downloaded file, generate a SHA-256 hash. This hash is a unique digital fingerprint of the file. If even a single pixel is later changed, the hash will change, proving to an editor that the evidence you collected has not been tampered with since collection.
Tool: Use a built-in command-line tool (
shasum -a 256 [filename]) or a reputable desktop hashing utility.
🧠 Verification and analysis for reporting
Corroboration Strategy
A single correlation point (e.g., a matching username) is insufficient for reporting. Journalistic standard requires two or more independent sources or methods.
Primary corroboration: The username match must be corroborated by a content/visual match (e.g., the same profile photo, the same detailed biographical information, or the exact unique quote).
Secondary corroboration: The correlated identity must then be validated against a third-party source (e.g., a public record, a corporate registry, or a verifiable event timeline).
Handling false positives: To eliminate common false positives (e.g., a common username shared by two different people), check the account’s creation date. If the correlated account predates the known activity window of your target by several years, the risk of a false match is high.
Translating a technical correlation into a clear, verifiable journalistic fact
🤖 AI Assistance in analysis
⚠️ IMPORTANT WARNING: The risk of hallucination and privacy
Journalists can use Large Language Models (LLMs) to process the publicly collected data, but only with extreme caution.
Summarizing large documents or log files: Upload collected, non-sensitive documents (e.g., a long public forum thread, a public log file) and ask the AI to extract five key themes or summarize the discussion around a specific event/entity. Example Prompt: “Analyze this log file and identify all unique timestamps and IP addresses mentioned. Do not interpret the data.”
Identifying key entities, dates, and relationships: Use AI for Named Entity Recognition (NER). Feed it large blocks of text and ask it to output a table of all unique names, organizations, and dates mentioned, helping to cluster data points.
Translation of foreign language material: LLMs are powerful translators for large-scale social media analysis, helping you spot critical keywords quickly.
⚠️ IMPORTANT WARNING: Hallucination and privacy risk
Hallucination risk: LLMs can invent facts and sources. Every single data point, summary, or translation provided by an AI must be fact-checked and verified manually against the original source before it can be used in reporting.
Privacy Risk: Never submit sensitive or source-provided data (e.g., internal leaks, confidential emails, witness statements) to public-facing AI/LLM models. These models may use your input data for training, compromising your investigation, your source, and the security of your publication. Use only local, firewalled, or commercially vetted enterprise AI solutions if dealing with sensitive material.
🚀 Next steps and practice
Exercise to practise
The “Vanishing Admin”: You are investigating a now-defunct political blog. Your only lead is the former site administrator’s signature: “j_w_admin.”
Correlate: Use a tool like WhatsMyName to check the core handle and two logical variants (e.g.,
jwadmin,j_w_admin81) against public platforms.Pivot: Assume you find a hit on an obscure image-hosting site. Pivot to reverse image search to see if the profile picture links to an active account.
Document: Capture a screenshot and generate a SHA-256 hash for all successful correlation points.
📖 More advanced resources
The OSINT Framework: A comprehensive, categorized directory of thousands of OSINT tools and resources for deeper pivots.
GHDB (Google Hacking Database): A list of advanced Google Dorks that can be adapted for finding specific file types or exposed data related to usernames/aliases.
Maltego: A powerful visual analysis tool for mapping relationships between entities (usernames, emails, IPs) found during correlation.
ExifTool: The gold-standard open-source tool for viewing and validating metadata in images and documents.
✅ Important things to remember and investigative principles
Public is primary: Stick exclusively to publicly available information; anything behind a login or requiring a technical exploit is illegal and not OSINT.
Correlate, don’t assume: A single match is a lead; a match corroborated by a second independent method (visual, behavioural, or content) is a high-confidence finding.
Pattern over presence: The strength of correlation lies in identifying reused patterns (photos, bios, phrases, timing) rather than just the same handle.
The audit trail is your defence: Document the Who, What, When, Where, and How of every discovery, and use SHA-256 hashing to prove the integrity of your collected evidence.
AI is an assistant, not an editor: Use AI for data processing and summarization, but manually fact-check every output and never submit sensitive data to public models.
👁️ Coming next week…
Uncovering deleted content with the internet archive toolkit
The next tutorial will equip you with the essential skills to battle digital disappearance. We will cover the advanced use of caching and archiving services like the Wayback Machine and Archive.is to retrieve ephemeral or deleted posts, websites, and documents. Learn how to reconstruct timelines and capture evidence of targets believed to be gone forever, ensuring accountability even after an entity attempts to scrub its digital footprint.
 | A guest post by
|